跳表
- 跳表在链表上加多级索引,查找/插入/删除平均 O(log n),用空间换时间
- 索引层数用随机函数决定(抛硬币),不需要严格维护,实现简单
- Redis ZSet 选跳表而不是红黑树:范围查询更简单、实现更简单、并发友好
1. 跳表是什么?
普通链表查询是 O(n),得一个个遍历。跳表的思路是在链表上加多级索引,用空间换时间,把查询效率提升到 O(log n)。
每隔几个节点抽一个节点出来组成上层索引,上层索引再抽,形成多层结构。查找时从最高层开始,快速跳过大段范围,再逐层下降精确定位。
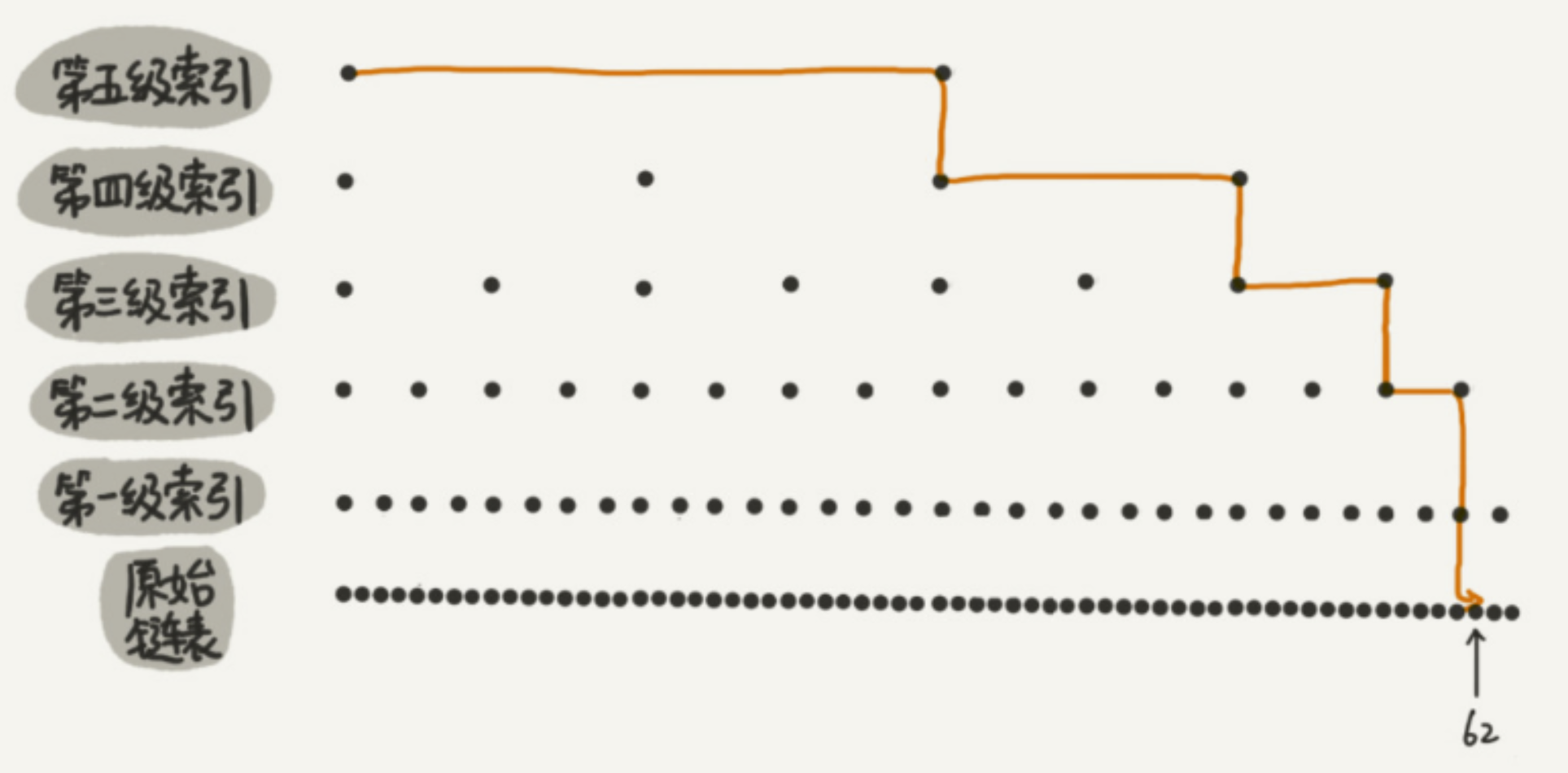
2. 查找过程
从最高层的头节点开始,向右比较:
- 右边节点的值 < 目标值:继续向右
- 右边节点的值 >= 目标值:下降一层,继续向右
- 到达最底层找到目标,或确认不存在
举个例子,在下面的跳表里找 17:
第2层:1 ---------> 13 ---------> 21
第1层:1 -----> 7 -> 13 -> 17 -> 21
第0层:1 -> 3 -> 7 -> 9 -> 13 -> 17 -> 21
从第 2 层出发:1 < 17,右移到 13;13 < 17,右移到 21;21 > 17,下降到第 1 层;
第 1 层:13 < 17,右移到 17,找到了。
只走了 5 步,而底层链表需要走 6 步,数据量越大优势越明显。
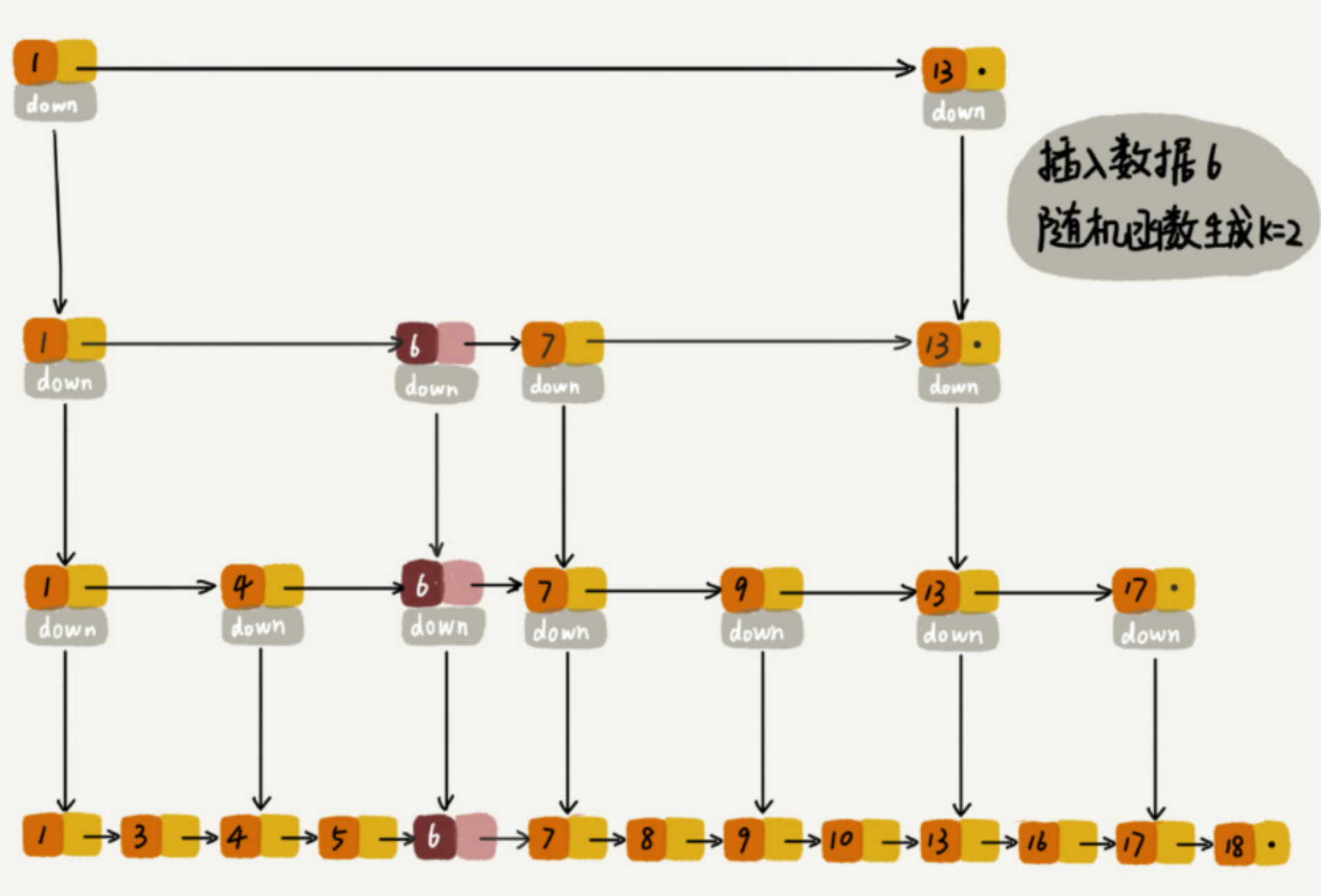
3. 插入过程
插入分两步:找到插入位置,然后决定新节点要建几层索引。
找位置和查找一样,记录每一层的前驱节点(后面要更新指针)。
索引层数用随机函数决定:每次抛硬币,正面就多加一层,反面就停。这样每个节点出现在第 k 层的概率是 (1/2)^k,期望层数是 2,整体结构保持平衡。
插入 15,随机到 2 层索引:
第2层:1 ---------> 13 -----> 15 -> 21
第1层:1 -----> 7 -> 13 -> 15 -> 17 -> 21
第0层:1 -> 3 -> 7 -> 9 -> 13 -> 15 -> 17 -> 21
4. 删除过程
找到目标节点,从最高层到最底层逐层摘除,更新前驱节点的 next 指针。如果某层删完后只剩头尾节点,可以把这层索引整体删掉,降低层高。
5. 为什么用随机而不是严格每隔 m 个建索引?
严格每隔 m 个建索引,插入和删除时需要维护所有索引节点,代价很高,最坏 O(n)。
随机层数的方式不需要严格维护,插入时只管自己要建几层,不影响其他节点。虽然结构不是绝对均匀,但概率上保证了 O(log n) 的期望性能,实现也简单很多。
6. 复杂度
| 操作 | 平均 | 最坏 |
|---|---|---|
| 查找 | O(log n) | O(n) |
| 插入 | O(log n) | O(n) |
| 删除 | O(log n) | O(n) |
| 空间 | O(n) | O(n log n) |
最坏情况是随机极度不均匀退化成链表,概率极低。空间上,每个节点平均有 2 个指针(等比数列求和),所以是 O(n)。
7. 跳表 vs 红黑树
跳表和红黑树的查找、插入、删除都是 O(log n),为什么 Redis 的有序集合(ZSet)选跳表而不是红黑树?
- 范围查询更简单:跳表底层是有序链表,范围查询直接在底层顺序遍历,红黑树需要中序遍历,实现复杂
- 实现更简单:跳表代码量远少于红黑树,出 bug 概率低,也更容易调试
- 并发友好:跳表的局部修改特性更容易实现无锁并发,红黑树旋转操作影响范围大
- 内存局部性:差不多,都不是连续内存
红黑树的优势是最坏情况严格 O(log n),跳表是概率保证。对于 Redis 这种场景,概率保证完全够用。
8. 实际应用
- Redis ZSet:有序集合底层,元素数量超过阈值(默认 128)时用跳表 + 哈希表实现
- LevelDB / RocksDB:MemTable 用跳表存储,写入快,顺序遍历高效
- Java ConcurrentSkipListMap:JDK 并发包里的跳表实现,线程安全的有序 Map