Raft协议原理
总结
- Raft 是强一致共识算法,Leader 处理所有写请求,超过半数节点确认才提交
- 选举靠随机超时避免平票,每个 term 每个节点只投一票
- 网络分区时少数派无法提交,分区恢复后回滚 uncommitted 日志从新 Leader 同步
- 和 Gossip 的区别:Raft 强一致适合元数据,Gossip 最终一致适合状态广播
1. Raft 是什么?
Raft 是一种分布式共识算法,用来保证多个节点之间的数据一致性。比 Paxos 更容易理解和实现,etcd、TiKV、Consul 都在用它。
节点有三种角色:
- Follower:初始状态,被动接收消息
- Candidate:发起选举中
- Leader:处理所有写请求,向 Follower 复制日志
2. Leader 选举
Follower 在随机超时时间(150~300 ms)内没收到 Leader 心跳,就转为 Candidate 发起选举:
- 自增 term(选举轮次),给自己投票
- 向其他节点发 RequestVote 请求
- 获得超过半数投票,成为 Leader
每个节点在同一个 term 内只能投一票,先到先得。用随机超时是为了避免多个节点同时发起选举导致平票,让某个节点先醒来拿到多数票。
3. 日志复制
写入流程:
客户端 → Leader 写入请求
Leader 写入本地日志(uncommitted)
Leader → 所有 Follower 发送日志(AppendEntries)
超过半数 Follower 返回 ACK
Leader 提交日志,回复客户端成功
Leader 下次心跳通知 Follower 提交
必须超过半数节点确认才能提交,这是强一致性的保证。5 个节点可以容忍 2 个挂掉。
4. 网络分区怎么处理?
假设 5 个节点,网络分区成两组:A+B 和 C+D+E,原 Leader 在 A 这边。
- A 这边只有 2 个节点,写入无法获得多数 ACK,变更保持 uncommitted
- C+D+E 这边超时后重新选举,C 成为新 Leader,term 更高,可以正常写入
网络恢复后,A 和 B 发现 C 的 term 更高,回滚自己 uncommitted 的日志,从 C 同步数据,集群恢复一致。
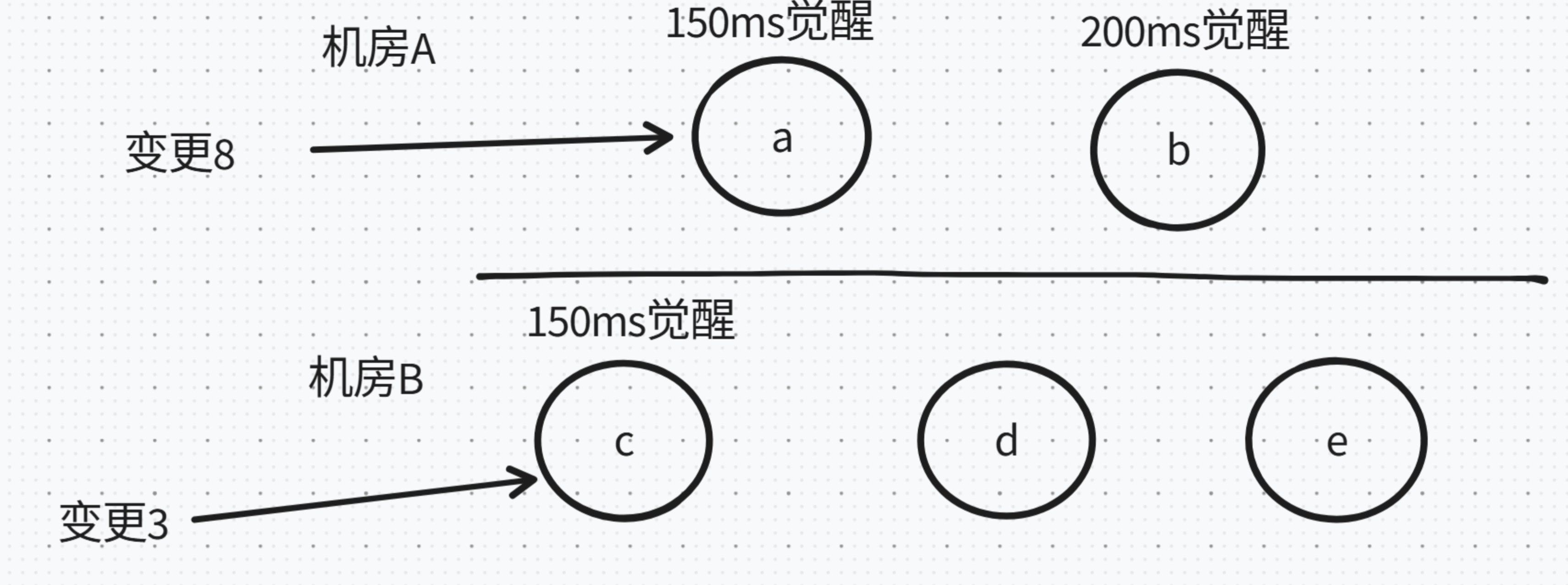
这也是 Redis 哨兵解决脑裂的底层逻辑,见 Redis哨兵与集群。
5. Raft vs Gossip
| Raft | Gossip | |
|---|---|---|
| 一致性 | 强一致 | 最终一致 |
| 架构 | Leader-Follower | 去中心化 |
| 写入 | 需要多数确认,延迟略高 | 传播快,延迟低 |
| 适合场景 | 配置管理、元数据存储 | 节点状态广播、服务发现 |
Redis Cluster 节点间状态传播用的是 Gossip,哨兵选主用的是类 Raft 投票机制。