01-初识MySQL
- Java 应用通过 JDBC 驱动连接 MySQL,生产环境用连接池复用连接
- 一条 SQL 经过:连接器 → 分析器 → 优化器 → 执行器,最终由存储引擎执行
- InnoDB 架构分三层:内存(Buffer Pool + Change Buffer)→ 日志(redo log)→ 磁盘
- 更新操作的完整链路:undo log(回滚)→ Buffer Pool(改内存)→ redo log(崩溃恢复)→ binlog(归档)
1. 驱动与连接池
Java 应用连 MySQL 靠的是 JDBC 驱动,本质上就是 TCP 长连接。每次查询都新建连接太慢了,所以生产环境都用连接池(HikariCP、Druid 等)复用连接。
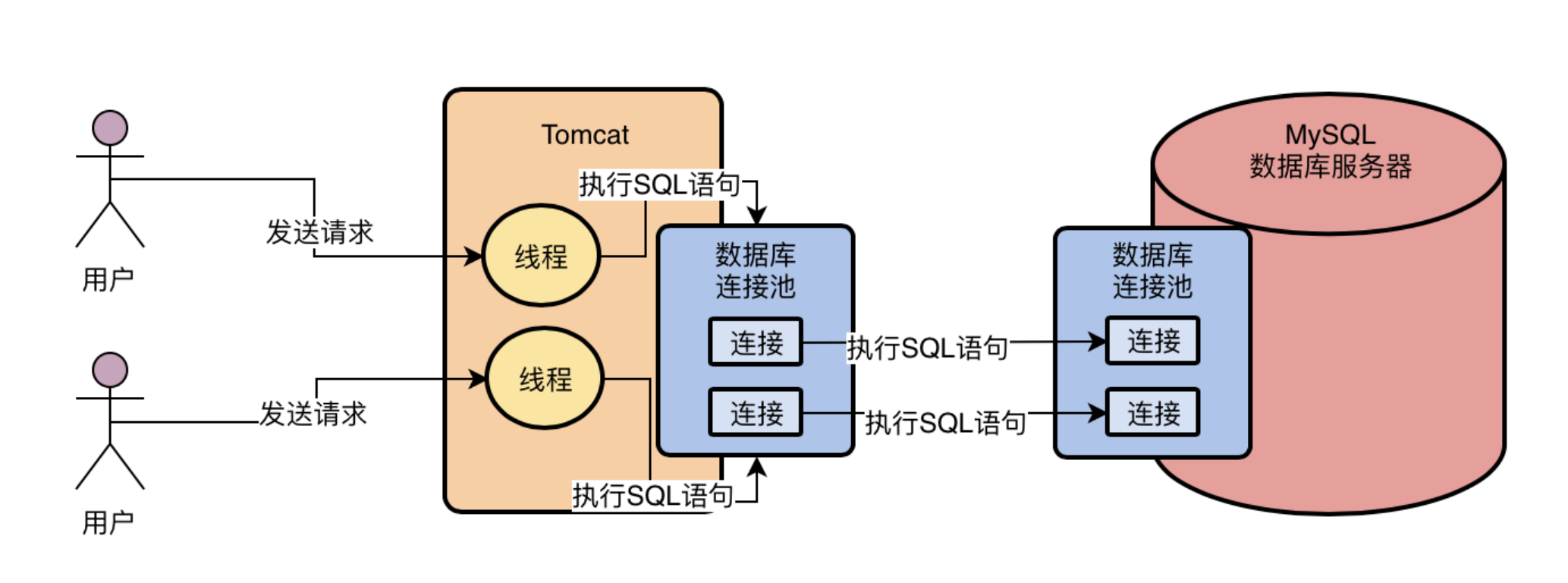
连接池的配置可以看 MySQL的JDBC与连接池调优。
2. 一条 SQL 怎么执行的?
你写一条 SELECT * FROM user WHERE id = 1,MySQL 内部的执行流程大概是这样:
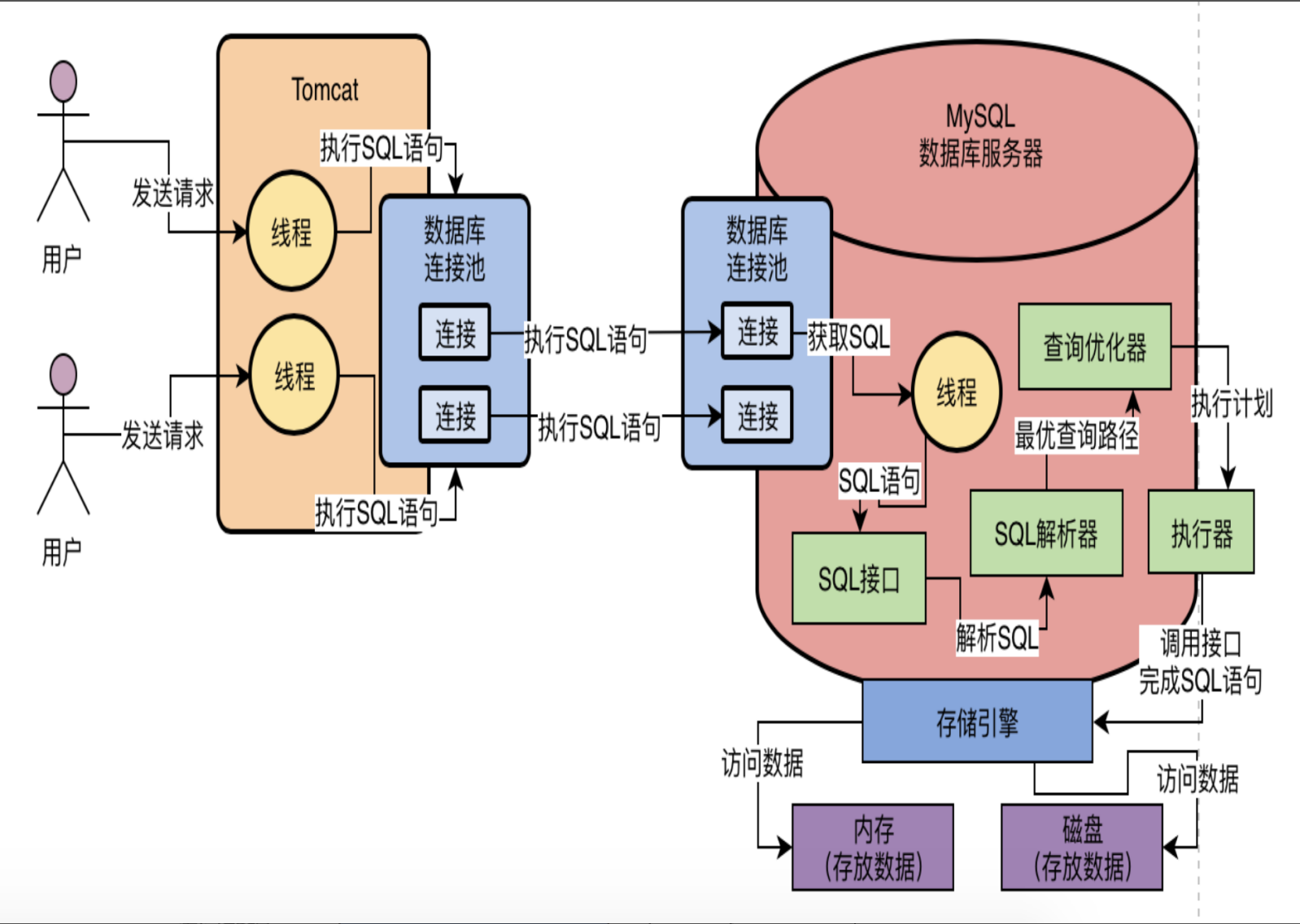
简单说就是:
- 连接器:先验证账号密码,看看你有没有权限
- 分析器:SQL 语法检查,生成解析树
- 优化器:决定用哪个索引、多表连接的顺序等
- 执行器:调用存储引擎的接口去拿数据
3. InnoDB 引擎长什么样?
MySQL 支持多种存储引擎,但日常开发基本都用 InnoDB。它的架构大概是这样:
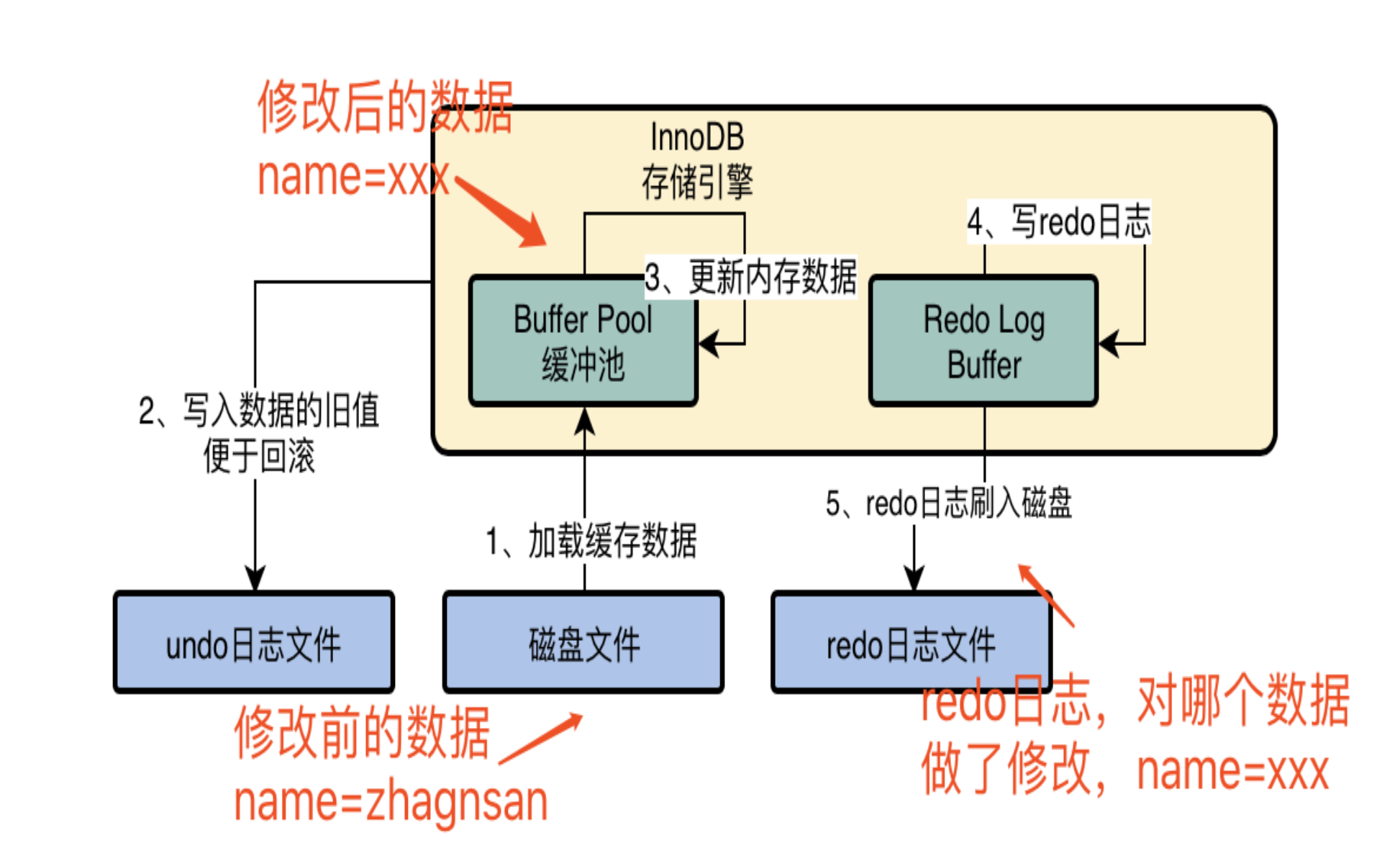
核心是三层结构:
内存层:Buffer Pool 是大头,数据页从磁盘加载到这里,后续读写都在内存操作。还有 Change Buffer 缓存非唯一索引的修改。
日志层:redo log 记录"对数据页做了什么修改",用于崩溃恢复。WAL(Write-Ahead Logging)机制,先写日志再写磁盘,保证数据不丢。
磁盘层:最终的数据文件(.ibd),redo log 最终也会刷到这里。
4. 更新操作的完整链路
以 UPDATE user SET name = '张三' WHERE id = 1 为例,完整流程:
- 加载数据页到 Buffer Pool(如果不在内存中)
- 写 undo log,记录修改前的值,用于事务回滚
- 更新 Buffer Pool 中的数据页
- 写 redo log(prepare 状态)
- 写 binlog
- 提交事务,redo log 标记 commit
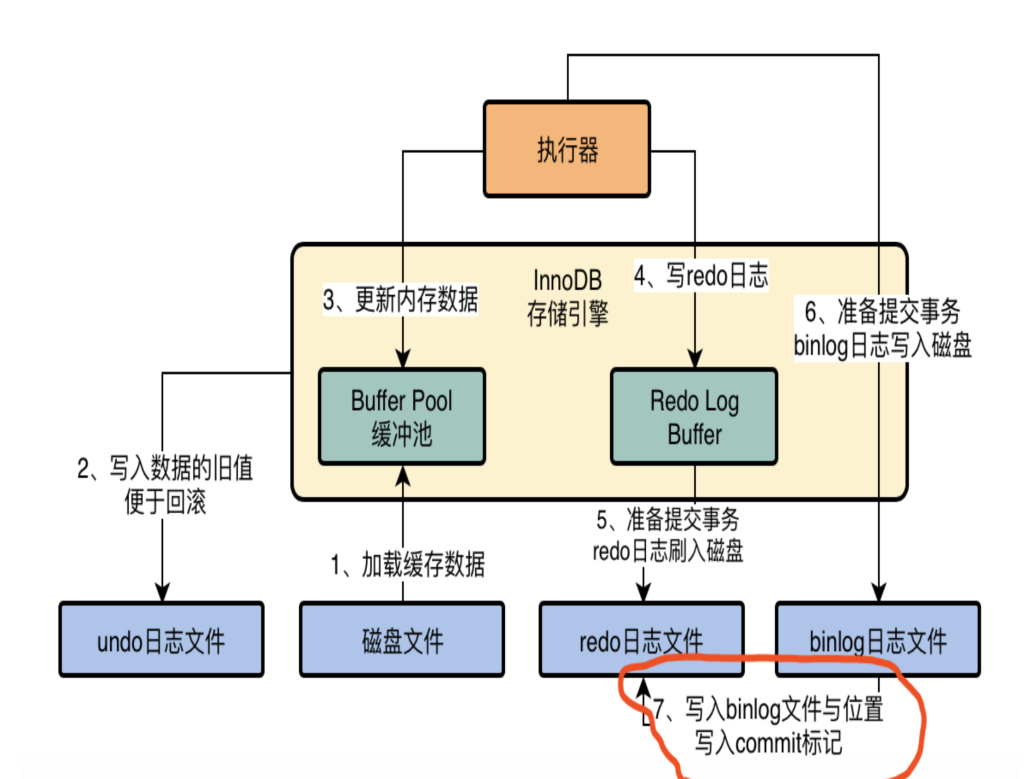
两阶段提交:保证 redo log 和 binlog 一致
为什么要分两步?这要从主从复制说起。
问题:如果只写完 redo log 就提交,binlog 还没写,此时 MySQL 挂了会怎样?
- 重启后: redo log 有记录,数据能恢复 ✓
- 从库同步: binlog 没有记录,数据不一致 ✗
反过来,如果只写完 binlog 就提交, redo log 还没写:
- 重启后:数据页没修改,但 binlog 有记录,数据不一致 ✗
- 从库同步:正常 ✓
两阶段提交就是解决这个问题的:
sequenceDiagram
participant App as 应用
participant DB as MySQL
participant Redo as redo log
participant Bin as binlog
App->>DB: UPDATE 语句
DB->>Redo: 1. 写 redo log (prepare)
DB->>Bin: 2. 写 binlog
DB->>Redo: 3. 标记 redo log (commit)
App->>DB: 返回成功崩溃恢复时的逻辑:
| 场景 | 处理 |
|---|---|
| redo log 有 prepare + commit | 正常,数据已提交 |
| redo log 有 prepare,无 commit | 检查 binlog,binlog 有则 commit,否则回滚 |
| redo log 无记录 | 未提交,直接回滚 |
这就是为什么 redo log 必须先 prepare,再写 binlog,最后 commit。这样无论哪个阶段崩溃,都能保证数据一致性。
redo log 刷盘策略
通过 innodb_flush_log_at_trx_commit 控制:
| 值 | 行为 | 适用场景 |
|---|---|---|
| 0 | 每秒写入 OS cache,由 OS 决定刷盘 | 性能最好,但可能丢 1 秒数据 |
| 1 | 每次事务提交都刷盘(默认) | 最安全,推荐生产用 |
| 2 | 写入 OS cache,由 OS 刷盘 | 介于 0 和 1 之间 |
建议:生产环境用 1,别省这点性能。
binlog 是什么?
redo log 是物理日志,记录"数据页第几行改了什么"。binlog 是逻辑日志,记录"对 user 表 id=1 的行做了更新"。
binlog 在 MySQL Server 层,主要用于:
- 主从复制:从库通过 binlog 同步数据
- 数据恢复:误删数据可以用 binlog 回放
binlog 的刷盘策略通过 sync_binlog 控制:
| 值 | 行为 |
|---|---|
| 0(默认) | 写入 OS cache,由 OS 刷盘 |
| 1 | 每次事务提交都强制落盘 |
建议:和 redo log 一样,sync_binlog = 1 配合使用,保证 redo log 和 binlog 一致。