10.Netty自定义协议实现
- 自定义协议比通用协议性能更好、扩展性更强,但要自己处理粘包/拆包
- 协议头固定长度,包含魔数、版本、序列化算法、报文类型、状态、数据长度等字段
- 编解码分一次和二次:ByteToMessageDecoder 解决粘包拆包,MessageToMessageDecoder 做对象转换
- 推荐用 LengthFieldBasedFrameDecoder 先拆包,再做业务解码,职责更清晰
- ReplayingDecoder 虽然简化了长度检查,但性能差,大部分场景不推荐
1. 为什么要自定义协议?
通用协议(HTTP、Protobuf 等)兼容性好,各种系统都能对接,优先考虑。但在以下场景下,自定义协议更合适:
| 对比维度 | 通用协议 | 自定义协议 |
|---|---|---|
| 性能 | 有兼容性开销 | 极致精简,按需设计 |
| 扩展性 | 受协议规范约束 | 完全自主,随业务演进 |
| 安全性 | 公开协议,漏洞已知 | 私有协议,攻击成本高 |
| 开发成本 | 低,有现成实现 | 高,需要自己实现编解码 |
2. 协议结构设计
一个典型的自定义 RPC 协议头:
+---------------------------------------------------------------+
| 魔数 2byte | 协议版本号 1byte | 序列化算法 1byte | 报文类型 1byte |
+---------------------------------------------------------------+
| 状态 1byte | 保留字段 4byte | 数据长度 4byte |
+---------------------------------------------------------------+
| 数据内容 (长度不定) |
+---------------------------------------------------------------+
各字段的作用:
| 字段 | 长度 | 作用 |
|---|---|---|
| 魔数 | 2byte | 防止非法数据包,收到数据先校验魔数,不对直接丢弃 |
| 协议版本号 | 1byte | 支持协议升级,不同版本走不同处理逻辑 |
| 序列化算法 | 1byte | 标识 Body 用哪种序列化:JSON、Hessian、Protobuf 等 |
| 报文类型 | 1byte | 区分消息类型:REQUEST、RESPONSE、HEARTBEAT 等 |
| 状态 | 1byte | 标识请求是否正常,由被调用方设置 |
| 保留字段 | 4byte | 预留给未来协议升级使用,当前填 0 |
| 数据长度 | 4byte | Body 的字节数,解码时用来判断数据是否读完整 |
魔数是防御的第一道门:客户端和服务端约定好一个固定的魔数值,收到数据包先校验魔数,不匹配直接关闭连接,避免处理非法数据。
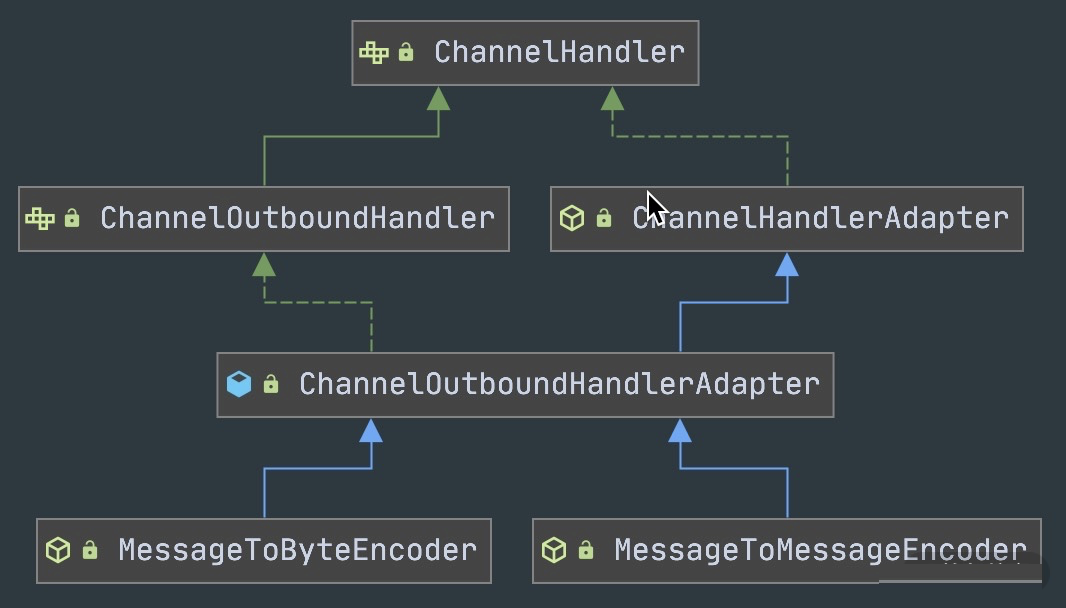
3. 编解码器类型
Netty 的编解码器分一次和二次,对应不同的处理阶段:
flowchart LR
subgraph 解码(入站)
A[ByteBuf\n原始字节] -->|ByteToMessageDecoder\n一次解码:解决粘包拆包| B[完整的 ByteBuf\n一个完整数据包]
B -->|MessageToMessageDecoder\n二次解码:字节转对象| C[业务对象\nRequest/Response]
end
subgraph 编码(出站)
D[业务对象] -->|MessageToByteEncoder\n一次编码| E[ByteBuf\n发送到网络]
end| 编解码器 | 方向 | 阶段 | 职责 |
|---|---|---|---|
ByteToMessageDecoder |
入站 | 一次解码 | 字节流 → 完整数据包,解决粘包/拆包 |
MessageToMessageDecoder |
入站 | 二次解码 | 完整数据包 → 业务对象 |
MessageToByteEncoder |
出站 | 一次编码 | 业务对象 → 字节流 |
MessageToMessageEncoder |
出站 | 二次编码 | 一种消息类型 → 另一种消息类型 |
MessageToMessageCodec |
双向 | 一次完成 | 同时处理编码和解码 |
3.1 ByteToMessageDecoder
public abstract class ByteToMessageDecoder extends ChannelInboundHandlerAdapter {
// 必须实现,处理粘包/拆包,解析出完整数据包放入 out
protected abstract void decode(ChannelHandlerContext ctx, ByteBuf in, List<Object> out) throws Exception;
// Channel 关闭时调用一次,处理最后剩余的字节,默认直接调用 decode()
protected void decodeLast(ChannelHandlerContext ctx, ByteBuf in, List<Object> out) throws Exception {
if (in.isReadable()) {
decodeRemovalReentryProtection(ctx, in, out);
}
}
}
decode() 的调用机制:TCP 粘包时 ByteBuf 里可能有多个完整报文,Netty 会反复回调 decode(),直到 List 没有新增元素或 ByteBuf 没有更多可读数据为止。解析出来的对象会传给 Pipeline 中下一个 Inbound Handler。
decodeLast() 在 Channel 关闭后调用一次,用于处理最后剩余的字节,有特殊需求时可以重写。
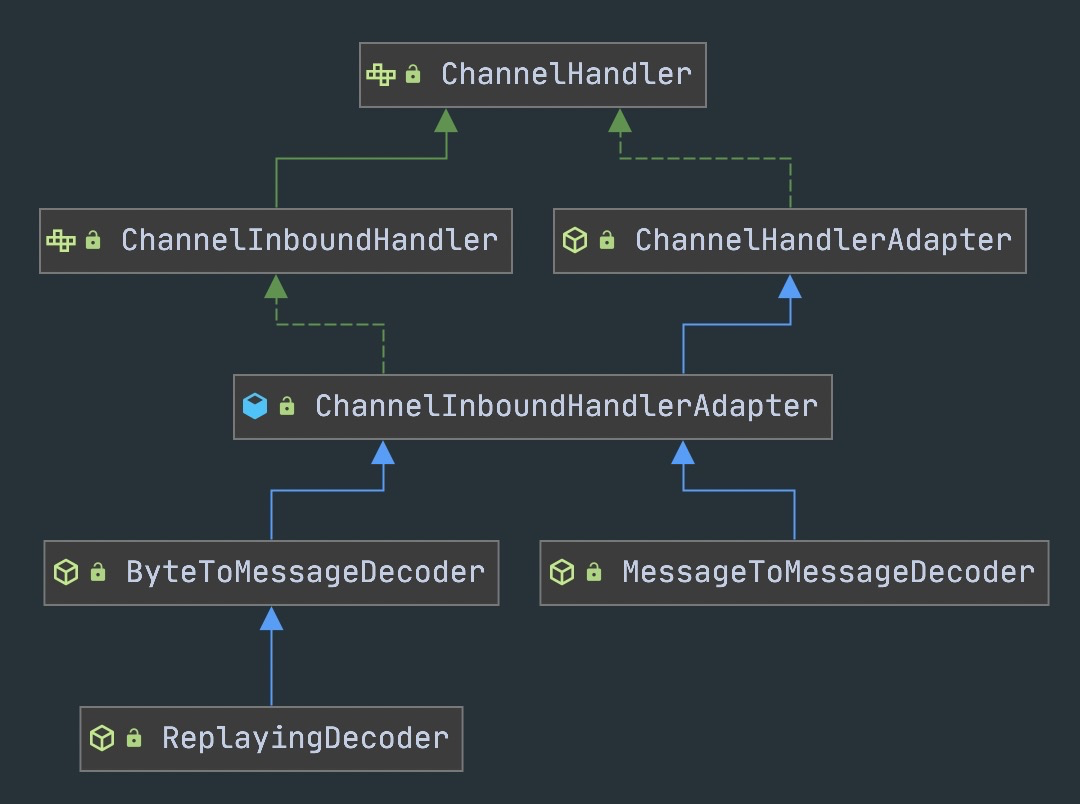
3.2 ReplayingDecoder
ReplayingDecoder 是 ByteToMessageDecoder 的子类,封装了缓冲区管理,读取时不需要手动检查字节长度——数据不够时会自动终止解码。
但它的性能比 ByteToMessageDecoder 差,大部分场景不推荐用,直接用 ByteToMessageDecoder 手动判断长度更可控。
4. 自定义解码器实现
用 ByteToMessageDecoder 实现协议解码,核心是两次长度检查:先判断头部够不够,再判断 Body 够不够:
public class MiniRpcDecoder extends ByteToMessageDecoder {
@Override
public final void decode(ChannelHandlerContext ctx, ByteBuf in, List<Object> out) throws Exception {
// 第一关:头部长度不够,等数据
if (in.readableBytes() < ProtocolConstants.HEADER_TOTAL_LEN) {
return;
}
in.markReaderIndex(); // 标记读指针,不够时可以回退
// 校验魔数,不对直接拒绝
short magic = in.readShort();
if (magic != ProtocolConstants.MAGIC) {
throw new IllegalArgumentException("magic number is illegal, " + magic);
}
byte version = in.readByte();
byte serializeType = in.readByte();
byte msgType = in.readByte();
byte status = in.readByte();
long requestId = in.readLong();
int dataLength = in.readInt();
// 第二关:Body 长度不够,回退读指针等数据
if (in.readableBytes() < dataLength) {
in.resetReaderIndex();
return;
}
byte[] data = new byte[dataLength];
in.readBytes(data);
MsgType msgTypeEnum = MsgType.findByType(msgType);
if (msgTypeEnum == null) return;
MsgHeader header = new MsgHeader();
header.setMagic(magic);
header.setVersion(version);
header.setSerialization(serializeType);
header.setStatus(status);
header.setRequestId(requestId);
header.setMsgType(msgType);
header.setMsgLen(dataLength);
RpcSerialization rpcSerialization = SerializationFactory.getRpcSerialization(serializeType);
switch (msgTypeEnum) {
case REQUEST:
MiniRpcRequest request = rpcSerialization.deserialize(data, MiniRpcRequest.class);
if (request != null) {
MiniRpcProtocol<MiniRpcRequest> protocol = new MiniRpcProtocol<>();
protocol.setHeader(header);
protocol.setBody(request);
out.add(protocol);
}
break;
case RESPONSE:
MiniRpcResponse response = rpcSerialization.deserialize(data, MiniRpcResponse.class);
if (response != null) {
MiniRpcProtocol<MiniRpcResponse> protocol = new MiniRpcProtocol<>();
protocol.setHeader(header);
protocol.setBody(response);
out.add(protocol);
}
break;
case HEARTBEAT:
// TODO 心跳处理
break;
}
}
}
两次长度检查是处理 TCP 粘包/拆包的标准套路:
- 头部不够 → 直接 return,等下次数据到来
- Body 不够 →
resetReaderIndex()回退,等下次数据到来
5. Netty 内置解码器
不想自己处理粘包拆包,可以直接用 Netty 内置的解码器:
| 解码器 | 适用场景 |
|---|---|
FixedLengthFrameDecoder |
每个数据包长度固定 |
DelimiterBasedFrameDecoder |
用特殊分隔符(如 \n)分割数据包 |
LengthFieldBasedFrameDecoder |
协议头里有长度字段,最通用 |
5.1 推荐做法:LengthFieldBasedFrameDecoder 先拆包
把拆包和业务解码分开,职责更清晰:
flowchart LR
A[原始 ByteBuf\n可能粘包/拆包] -->|LengthFieldBasedFrameDecoder\n按长度字段切割| B[完整的一帧 ByteBuf]
B -->|MiniRpcDecoder\n只做业务解码| C[MiniRpcProtocol 对象]这样 MiniRpcDecoder 里就不需要再判断长度了,收到的 ByteBuf 一定是完整的一帧。
// Pipeline 配置
pipeline.addLast(new LengthFieldBasedFrameDecoder(
Integer.MAX_VALUE, // 最大帧长度
12, // 长度字段偏移量(跳过魔数+版本+序列化+报文类型+状态+requestId)
4, // 长度字段本身占 4 字节
0, // 长度字段后的调整量
0 // 从帧头开始,不跳过任何字节
));
pipeline.addLast(new MiniRpcDecoder());
pipeline.addLast(new MiniRpcEncoder());
pipeline.addLast(new RpcRequestHandler());
5.2 带魔数校验的 LengthFieldBasedFrameDecoder
继承 LengthFieldBasedFrameDecoder 加上魔数校验,非法数据包直接丢弃:
public class Spliter extends LengthFieldBasedFrameDecoder {
private static final int LENGTH_FIELD_OFFSET = 4;
private static final int LENGTH_FIELD_LENGTH = 2;
private static final int MAGIC_NORTH_NUMBER = 0xeb90eb90;
// 小端字节序(低位字节在前)
public Spliter() {
super(ByteOrder.LITTLE_ENDIAN, Integer.MAX_VALUE,
LENGTH_FIELD_OFFSET, LENGTH_FIELD_LENGTH, 0, 0, true);
}
@Override
protected Object decode(ChannelHandlerContext ctx, ByteBuf in) throws Exception {
// 魔数不对,丢弃数据包
if (in.getInt(in.readerIndex()) != MAGIC_NORTH_NUMBER) {
log.info("数据包格式错误,不进行处理");
return null;
}
return super.decode(ctx, in);
}
}
注意 ByteOrder.LITTLE_ENDIAN:Netty 默认大端字节序,如果对端用小端序,需要显式指定,否则读出来的长度字段会是错的。