03-磁盘存储结构
- 表结构设计:知道 varchar 会记录长度、NULL 会占 bit 位,建表时就能避免不必要的 NULL 字段,控制 varchar 长度防止行溢出
- 性能优化:理解数据页是 16KB、读写以页为单位,就明白为什么频繁随机读取小数据效率低,从而优化查询方式或调整索引策略
- 存储空间估算:知道每行有变长字段列表、NULL 值列表、40bit 头字段等额外开销,能更准确地估算表占用的磁盘空间
- 故障排查:了解表空间的层级结构(表空间→组→区→页),在遇到磁盘空间问题或数据损坏时,能更好地定位问题范围
- 理解 MVCC:通过隐藏字段 DB_TRX_ID 和 DB_ROLL_PTR,能更深入理解事务和 MVCC 的实现机制
1. 数据页
InnoDB 把磁盘数据组织成一页一页的,每页 16 KB。读数据时至少加载一页到内存,写数据时也是在内存里改完再刷回磁盘。
2. 行数据怎么存的?
一行数据在磁盘上不是简单地存字段值,还有一堆元信息。InnoDB 用 COMPACT 行格式来组织:
CREATE TABLE table_name (columns) ROW_FORMAT=COMPACT;
ALTER TABLE table_name ROW_FORMAT=COMPACT;
存储结构从左到右:
变长字段长度列表 | NULL 值列表 | 头字段 | 真实数据
2.1 变长字段长度列表
varchar 类型的字段长度不固定,需要记录每个变长字段实际占了多少字节。
比如有 varchar(10), varchar(5), varchar(20),实际存的是 "hello", "hi", "hao",长度分别是 5、2、3。
存储时逆序排列(猜测是栈的方式处理):
实际存储: 0x03 0x02 0x05 | NULL值列表 | 头字段 | hello hi hao ...
2.2 NULL 值怎么存?
允许为 NULL 的字段,用一个 bit 位来标识:1 表示 NULL,0 表示非 NULL。
举个例子:
CREATE TABLE customer (
name VARCHAR(10) NOT NULL,
address VARCHAR(20),
gender CHAR(1),
job VARCHAR(30),
school VARCHAR(50)
) ROW_FORMAT=COMPACT;
如果插入的数据是 jack, NULL, m, NULL, xx_school,有 4 个字段可以为 NULL(address、gender、job、school),值分别是 NULL、非 NULL、NULL、非 NULL。
二进制表示:00000101(倒序补足 8 位),存储为 0x05。
详细解释:
- 字段顺序:address、gender、job、school(共4个可为NULL的字段)
- 对应NULL值:address(NULL→1)、gender(非NULL→0)、job(NULL→1)、school(非NULL→0)
- NULL值列表按字段顺序逆序存储:school、job、gender、address
- 每个字段对应一个bit位(1表示NULL,0表示非NULL),得到序列:0(school)、1(job)、0(gender)、1(address)
- 将这个4位序列放到一个字节的低4位,高位补0,得到:
00000101 - 转换为十六进制:
0x05
因此,NULL值列表存储为1个字节 0x05。
2.3 40 bit 头字段
头字段占 5 个字节(40 bit),记录了这行数据的各种元信息:
| bit 位置 | 字段 | 说明 |
|---|---|---|
| 1-2 | 预留位 | 没有意义 |
| 3 | delete_mask | 这行是否被删除(标记删除) |
| 4 | min_rec_mask | B+树非叶子节点的最小值标记 |
| 5-8 | n_owned | 该记录拥有的记录数 |
| 9-21 | heap_no | 这行数据在堆中的位置 |
| 22-24 | record_type | 数据类型:0 普通、1 B+树非叶、2 最小值、3 最大值 |
| 25-40 | next_record | 下一条记录的指针(16 bit) |
next_record 就是页内数据行之间用链表串起来的指针,所以遍历一页里的数据其实是沿着链表走的。
示例: 对于前面的示例数据(jack, NULL, m, NULL, xx_school),假设这是一条普通记录,未被删除,且是该页中的第一条用户记录(heap_no=2),没有下一条记录(next_record=0)。
| 字段 | 值 | 二进制表示 | 说明 |
|---|---|---|---|
| 预留位 | 0 | 00 | 无意义 |
| delete_mask | 0 | 0 | 未删除 |
| min_rec_mask | 0 | 0 | 非B+树最小值标记 |
| n_owned | 0 | 0000 | 普通记录,不拥有其他记录 |
| heap_no | 2 | 0000000000010 | 堆中位置(第2个记录) |
| record_type | 0 | 000 | 普通记录 |
| next_record | 0 | 0000000000000000 | 无下一条记录 |
连接所有位:00 0 0 0000 0000000000010 000 0000000000000000
按字节分组:00000000 00000000 00000010 00000000 00000000
十六进制表示:0x0000020000(5字节)
实际存储时,这5个字节按顺序写入磁盘,无字节序转换。
2.4 隐藏字段
除了用户定义的字段,InnoDB 还会自动加三个隐藏字段:
| 字段 | 说明 |
|---|---|
| DB_ROW_ID | 行的唯一标识。没指定主键时,InnoDB 用这个当主键 |
| DB_TRX_ID | 最后修改这行的事务 ID |
| DB_ROLL_PTR | 回滚指针,指向 undo log,用于 MVCC |
3. 行溢出
一行数据不能无限长。如果一行数据太大(比如 varchar(65532)),单个 16 KB 的页放不下,就会发生行溢出。
溢出的部分会存到单独的溢出页里,行数据里只保留一个指针指向溢出页。
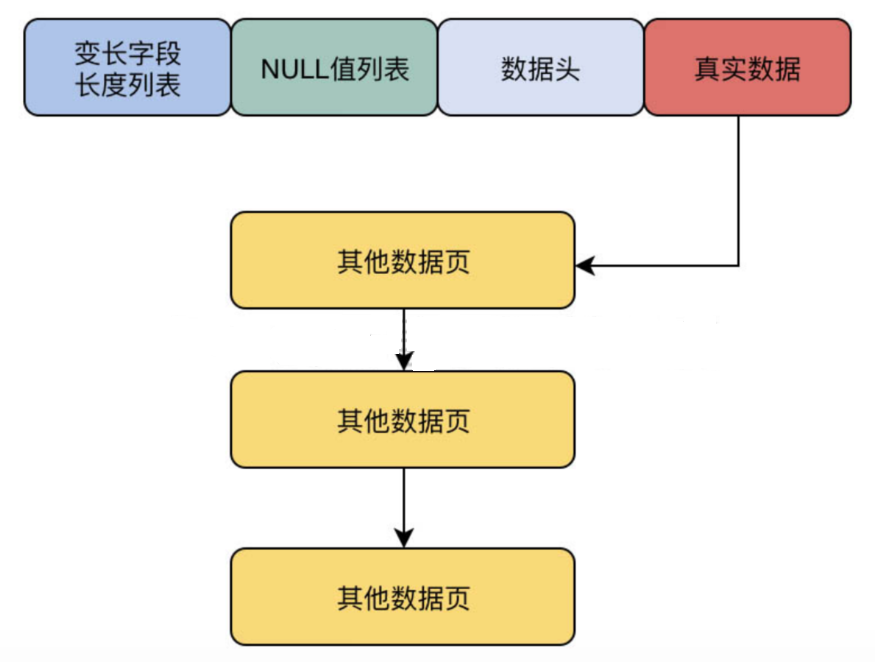
所以实际开发中,别把 varchar 设得太大,尽量控制在合理范围内。
4. 表空间
平时建的每张表都有对应的表空间,对应磁盘上的 .ibd 文件。表空间里的数据按层级组织:
表空间
└── 组(256 个区)
└── 区(1MB,64 个页)
└── 页(16KB)
第一组数据区的第一个数据区,前三个数据页存放特殊信息(比如数据区的描述信息)。
执行增删改查时,就是从表空间的 .ibd 文件里加载数据页到 Buffer Pool 的缓存页里使用。