CPU中的伪共享
- CPU 按缓存行(64字节)批量加载数据,多线程修改同一缓存行的不同变量会触发 MESI 失效,造成伪共享
- 解决办法:手动 Padding 填充、
@Contended注解、或直接用LongAdder - 普通业务不用特别处理,高并发计数器、环形队列等场景才需要关注
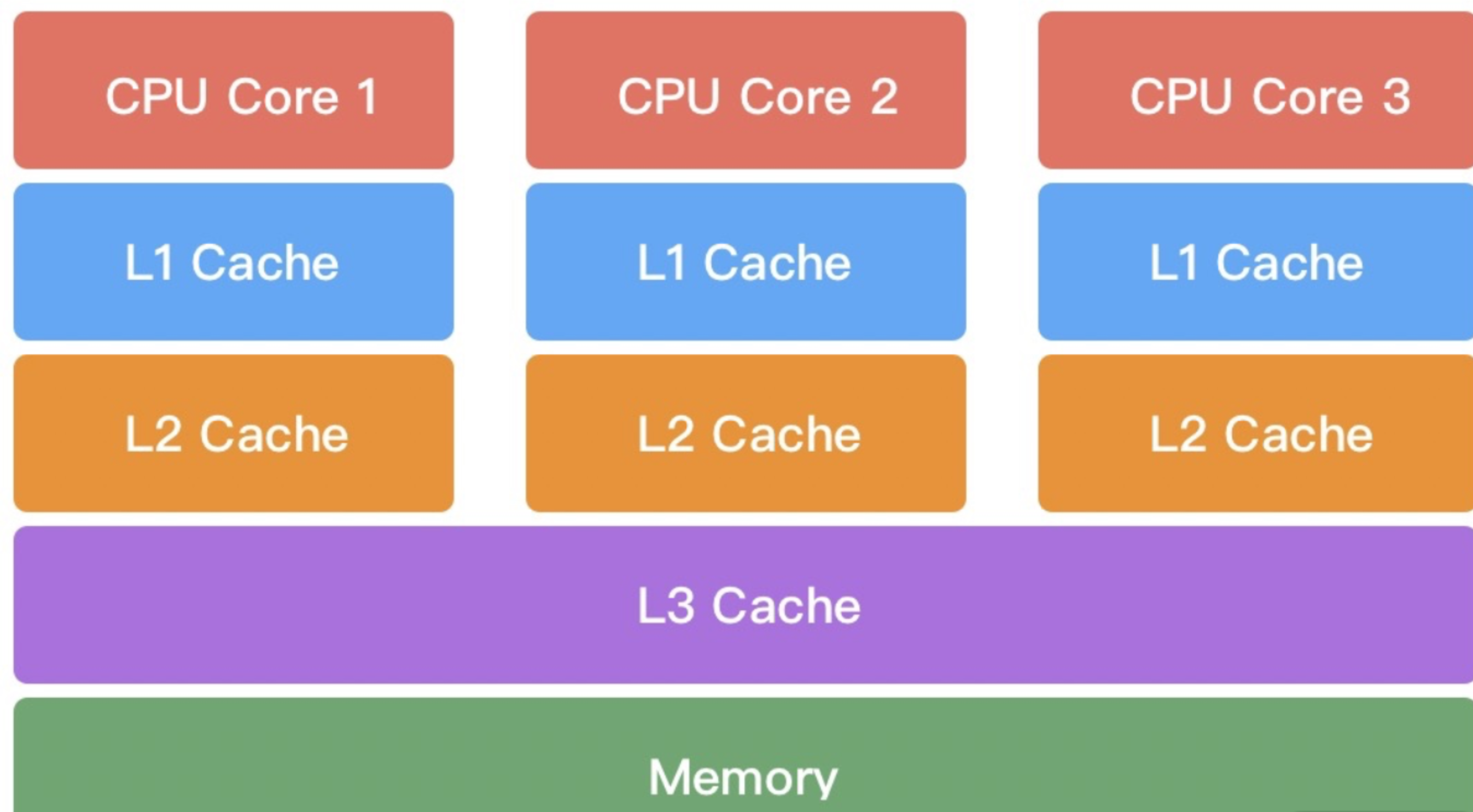
1. Cache Line 是什么?
CPU 读内存不是一个字节一个字节读的,而是按缓存行(Cache Line)为单位批量加载。Cache Line 是 CPU 缓存可操作的最小单位,大小通常是 64 字节(主流 64 位架构)。
Java 里一个 long 是 8 字节,所以一个 Cache Line 能装下 8 个 long。
CPU 加载数据时,会把目标数据连同相邻的数据一起读进 Cache Line,因为相邻数据被访问的概率很高,这样能减少 CPU 频繁去内存取数据的次数。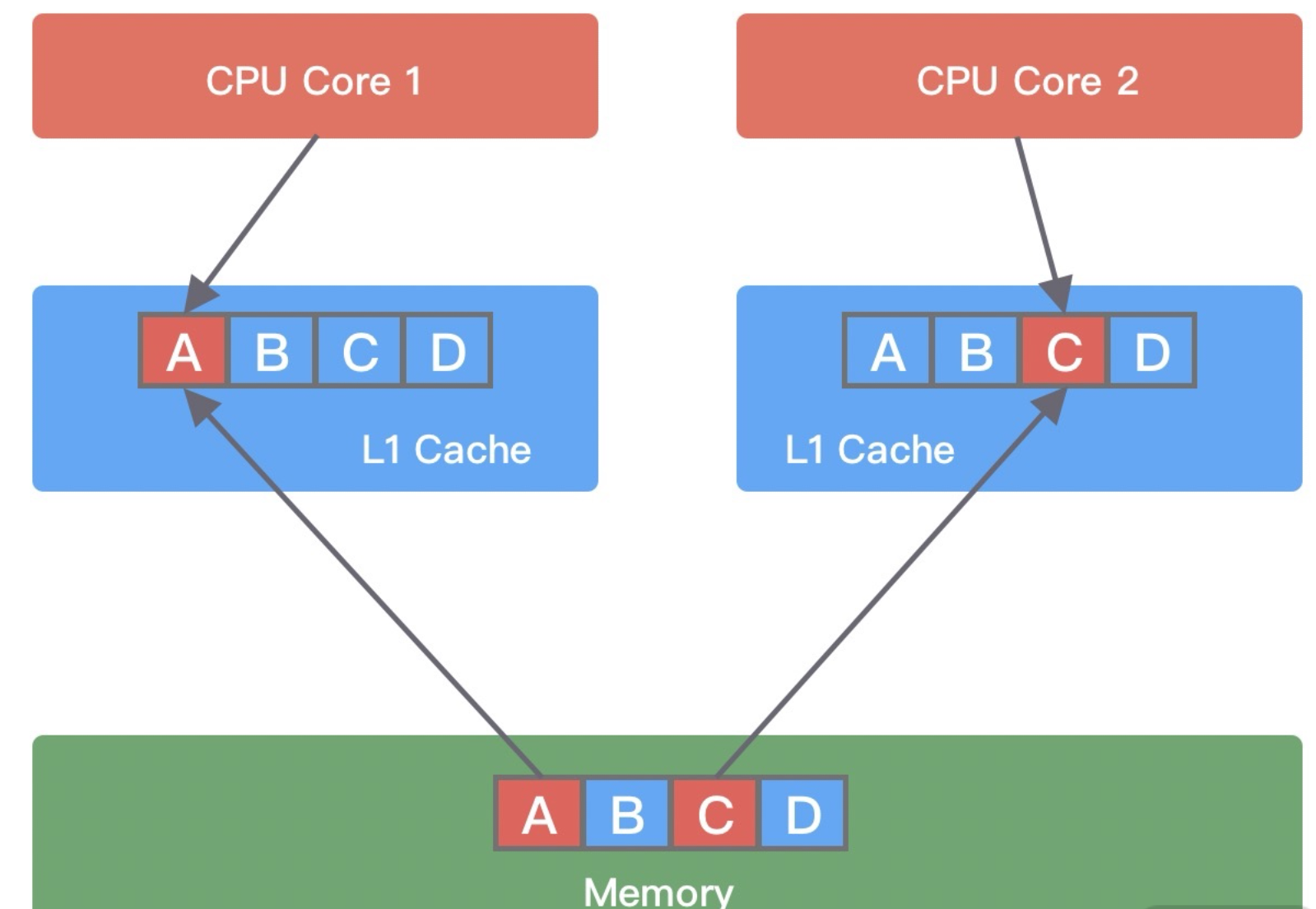
2. 什么是伪共享?
假设变量 A、B、C、D 在内存里紧挨着,被加载到了同一个 Cache Line。
现在多个线程分别修改这些变量:
线程 1(Core 1)修改变量 A
线程 2(Core 2)修改变量 C
问题来了:
- 线程 1 修改 A 后,Core 1 通过 MESI 协议广播通知其他核:这条缓存行失效了
- 线程 2 想改 C,发现自己的 Cache Line 已经失效
- Core 2 只能等 Core 1 把数据写回内存,再重新从内存加载整条 Cache Line
- 线程 2 改完 C,又触发一轮失效通知……
A 和 C 根本不是同一个变量,线程之间也没有逻辑上的共享,但因为住在同一条 Cache Line 里,互相干扰了对方的缓存——这就是伪共享(False Sharing)。
同一条 Cache Line 被越多线程频繁修改,写竞争就越激烈,数据反复在内存和缓存之间来回搬,性能白白浪费。
3. MESI 协议怎么保证缓存一致?
多核 CPU 每个核都有自己的 L 1/L 2 缓存,MESI 协议用来保证各核缓存的一致性。
每条 Cache Line 有四种状态:
| 状态 | 含义 |
|---|---|
| Modified | 被当前核修改过,数据与内存不一致,其他核没有这份数据 |
| Exclusive | 只有当前核有,与内存一致,未被修改 |
| Shared | 多个核都有这份数据,与内存一致 |
| Invalid | 缓存行已失效,数据不可用 |
当某个核修改了 Cache Line,会通过总线广播让其他核把对应缓存行标记为 Invalid,其他核下次访问时就得重新从内存(或发出修改的核)加载数据。
伪共享的性能损耗,本质上就是 MESI 协议在频繁触发缓存失效和重新加载。
4. 怎么解决伪共享?
核心思路:让不同线程操作的变量不要落在同一条 Cache Line 里。
4.1 手动填充(Padding)
在变量前后填充无用字段,把变量撑到独占一条 Cache Line:
public class PaddedValue {
// 前置填充,7 个 long = 56 字节
long p1, p2, p3, p4, p5, p6, p7;
// 真正的数据,8 字节,合计 64 字节独占一条 Cache Line
volatile long value;
// 后置填充,防止与下一个对象的字段共享
long p8, p9, p10, p11, p12, p13, p14;
}
4.2 用 @Contended 注解(推荐)
JDK 8 引入了 @sun.misc.Contended,JVM 会自动在字段前后插入填充,不用手动写:
public class ContendedValue {
@sun.misc.Contended
volatile long value;
}
需要加 JVM 参数
-XX:-RestrictContended才能生效。
JDK 内部很多地方用了这个注解,比如 Thread 类里的随机数字段、LongAdder 的 Cell 数组。
4.3 用 LongAdder 替代 AtomicLong
LongAdder 内部就是用 @Contended 解决了伪共享问题,高并发累加场景下性能比 AtomicLong 好很多,直接用就行,不用自己处理。
5. 什么时候需要关注?
不是所有场景都值得优化,伪共享主要在这几种情况下影响明显:
- 高并发下多个线程频繁写不同变量,但这些变量在内存里紧挨着
- 数组里相邻元素被不同线程同时修改(比如计数器数组、环形队列)
- 性能敏感的基础组件,比如队列、调度器
普通业务代码一般不用特别处理,优先用 LongAdder 这类已经处理好的工具类就行。