TCP传输中粘包拆包问题
- TCP 是面向字节流的协议,没有消息边界,粘包/拆包是必然现象,不是 Bug
- 拆包原因:数据超过 MSS 或滑动窗口大小,被拆成多个包发送
- 粘包原因:Nagle 算法把多个小包合并成一个大包发送
- 解决方案三种:固定长度、分隔符、消息头+长度字段(最常用,本质是自定义协议)
- Netty 默认禁用 Nagle 算法,并内置了三种解码器对应三种解决方案
1. 什么是粘包和拆包
TCP 是面向字节流的协议,数据在传输时是连续的字节序列,没有天然的消息边界。发送方发出的多条消息,接收方读到的可能是:
- 粘包:两条消息合并成一条读到了
- 拆包:一条消息被分成多次才读完
- 混合:部分粘包 + 部分拆包同时出现
发送方发送:[消息A][消息B][消息C]
接收方可能读到:
情况1(正常):[消息A] [消息B] [消息C]
情况2(粘包):[消息A + 消息B] [消息C]
情况3(拆包):[消息A前半] [消息A后半 + 消息B] [消息C]
这不是 Bug,是 TCP 协议的设计特性,应用层必须自己处理消息边界。
2. 为什么会发生
2.1 拆包:数据超过 MSS
MTU(Maximum Transmission Unit) 是链路层一次最大传输的数据量,以太网通常是 1500 字节。
MSS(Maximum Segment Size) 是 TCP 层一次最大发送的数据量,计算关系为:
MSS = MTU - IP 首部(20字节)- TCP 首部(20字节)= 1460 字节
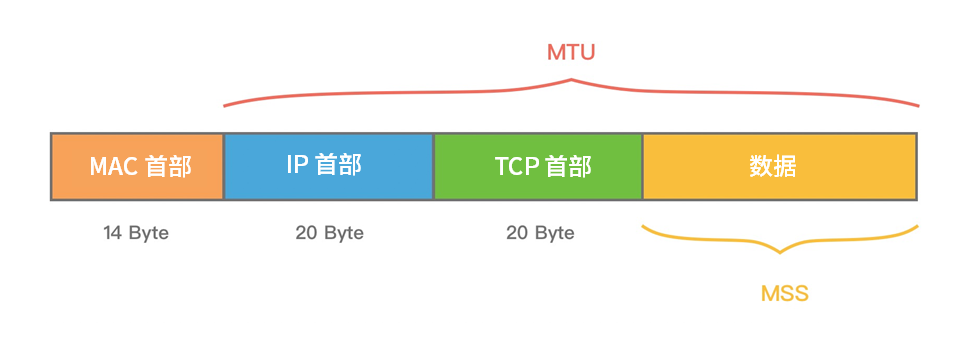
如果应用层发送的数据超过 MSS,TCP 会自动把它拆成多个报文段分批发送,接收方就会看到拆包现象。
2.2 拆包:滑动窗口限制
滑动窗口是 TCP 的流量控制机制,接收方会告诉发送方自己当前能接收多少数据(窗口大小)。如果发送方的数据量超过接收方的窗口大小,也会被拆分发送。
滑动窗口同时保证了数据的有序性:所有报文段都有编号,接收方必须按序确认,乱序到达的报文段会被暂存,等缺失的补齐后再一起交给应用层。
2.3 粘包:Nagle 算法
Nagle 算法是 TCP 的拥塞控制优化,核心思路是批量发送:
在上一批数据未收到 ACK 确认之前,把新来的小数据先写入缓冲区,等收到 ACK 或缓冲区积累到足够大,再一次性发出去。
这样可以把多个小包合并成一个大包,减少网络包数量,降低开销。但副作用就是粘包,以及引入了一定的发送延迟。
Linux 默认开启 Nagle 算法。对延迟敏感的场景(如实时游戏、交易系统)可以通过 TCP_NODELAY 参数禁用。Netty 为了最小化传输延迟,默认禁用了 Nagle 算法,与 Linux 默认行为相反。
3. 解决方案
本质都是在应用层定义消息边界,让接收方知道一条消息从哪里开始、到哪里结束。
3.1 固定长度
每条消息固定为 N 字节,不足则补齐,接收方每次读 N 字节就是一条完整消息。
[消息A: 固定64字节][消息B: 固定64字节][消息C: 固定64字节]
缺点:消息长度不一致时浪费空间,灵活性差,实际很少用。
Netty 对应:FixedLengthFrameDecoder
3.2 特殊分隔符
在每条消息末尾加上特定分隔符(如 \n、\r\n),接收方按分隔符切割。
消息A内容\n消息B内容\n消息C内容\n
缺点:消息内容本身不能包含分隔符,否则需要转义,处理起来麻烦。适合文本协议(如 HTTP 响应头、Redis 协议)。
Netty 对应:DelimiterBasedFrameDecoder
3.3 消息头 + 长度字段(推荐)
在消息前面加一个固定长度的消息头,头部包含消息体的长度,接收方先读头部拿到长度,再读对应字节数的消息体。
[4字节长度][消息A内容][4字节长度][消息B内容][4字节长度][消息C内容]
这本质上就是自定义应用层协议,也是 RPC 框架、消息队列等中间件普遍采用的方式。灵活性最好,消息内容没有任何限制。
Netty 对应:LengthFieldBasedFrameDecoder,可以灵活配置长度字段的位置和大小。
4. 三种方案对比
| 方案 | 灵活性 | 实现复杂度 | 适用场景 |
|---|---|---|---|
| 固定长度 | 低 | 简单 | 消息长度固定的简单协议 |
| 特殊分隔符 | 中 | 中等 | 文本协议,内容不含分隔符 |
| 消息头+长度 | 高 | 中等 | 二进制协议、RPC、消息队列 |