02-BufferPool与内存管理
- Buffer Pool 是 InnoDB 的核心内存组件,默认 128MB,生产环境要调大
- 内部三套链表:free(空闲页)、flush(脏页)、lru(淘汰顺序)
- LRU 采用冷热分离设计,避免预读和全表扫描污染热点数据
- 具体配置和验证方法见 Buffer Pool配置调优
1. Buffer Pool 是干嘛的?
简单说就是 InnoDB 的数据缓存区。你查数据、改数据,都是先把磁盘上的页(page)加载到 Buffer Pool 里,然后在内存里操作。操作完不一定马上写回磁盘,有个后台线程定期刷盘。
所以 Buffer Pool 越大,能缓存的数据越多,磁盘 IO 就越少,性能自然好。但也不能太大,得给操作系统、其他进程、连接栈内存等留够空间。
2. 里面存的是什么?
存的是数据页,磁盘上的数据页大小是 16KB,Buffer Pool 里的缓存页跟它一一对应。
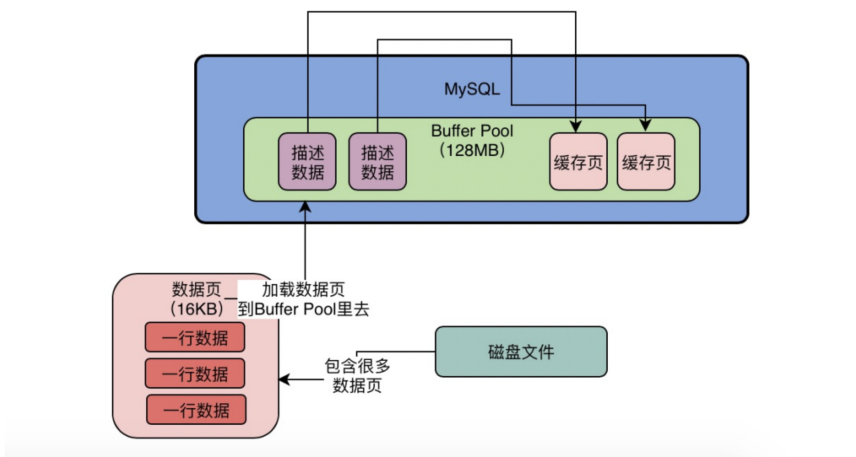
每个缓存页都有一个描述信息(大概占缓存页大小的 5%-8%),记录了这个数据页属于哪个表空间、页编号是多少、在 Buffer Pool 的地址等元数据。
3. 三套链表
Buffer Pool 内部用三套链表管理缓存页:
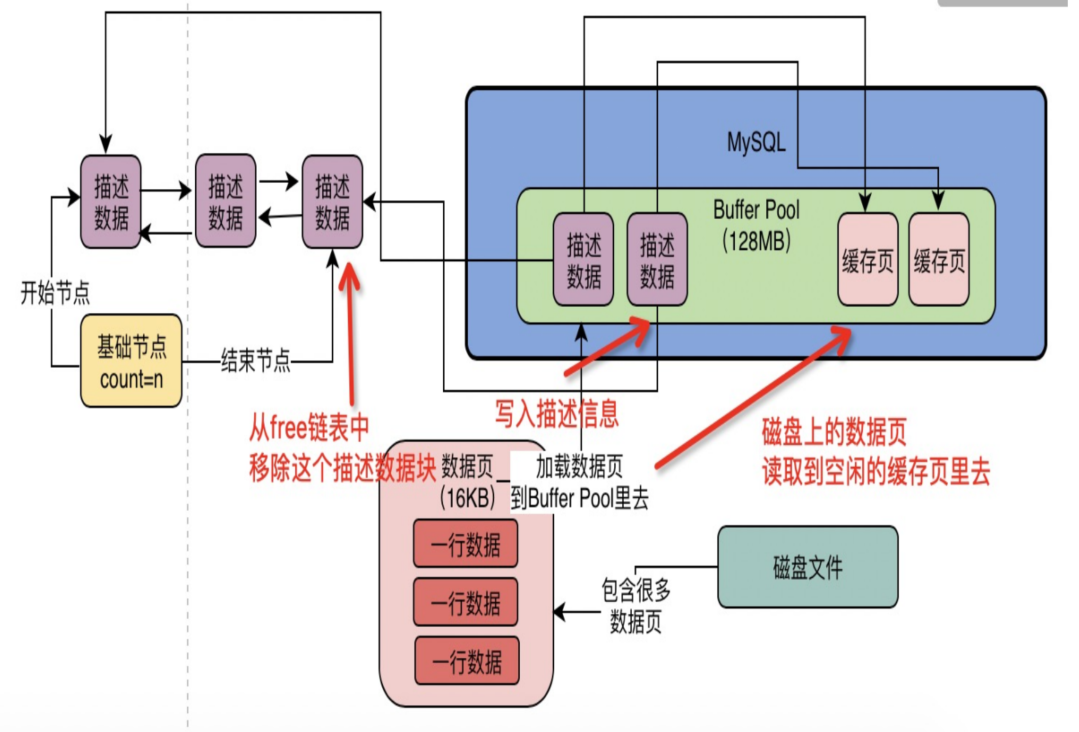
3.1 free 链表:空闲页在哪?
用一个哈希表记录哪些缓存页是空闲的。key 是 表空间 + 数据页号,value 是缓存页地址。
要加载新数据页时,先查哈希表,如果没有就从磁盘加载进来。
3.2 flush 链表:哪些是脏页?
你更新了 Buffer Pool 里的数据页,但还没刷回磁盘,这页就是脏页(跟磁盘不一致)。
flush 链表就是专门记录这些脏页的,方便后续批量刷盘。
3.3 lru 链表:淘汰谁?
用来管理缓存页的访问顺序,内存满了就从尾部淘汰。但 MySQL 的 LRU 不是简单的 LRU,而是冷热分离设计(见第 4 节)。
LRU 是双向链表,通过 3 个关键指针来管理:
lru_old 指针
↓
热数据区头部 ←→ ... ←→ 分界点 ←→ ... ←→ 冷数据区尾部
↑头部指针 ↑尾部指针
| 指针 | 作用 |
|---|---|
| 头部指针 | 热数据区入口,提升的页插入到这里 |
| lru_old 指针 | 冷热分界点,新加载的页插入到这个位置(冷数据区头部) |
| 尾部指针 | 冷数据区末端,淘汰时从这里踢 |
每个节点自身的 prev/next 指针维护双向连接,保证核心操作都是 O(1):新页加载插到 lru_old 位置,页提升插到头部,淘汰从尾部踢出。
4. LRU 的冷热分离设计
普通 LRU 有个问题:预读机制或者全表扫描会把大量冷数据加载进来,把真正的热点数据挤出去。
MySQL 的解法是把 LRU 链表拆成两部分:
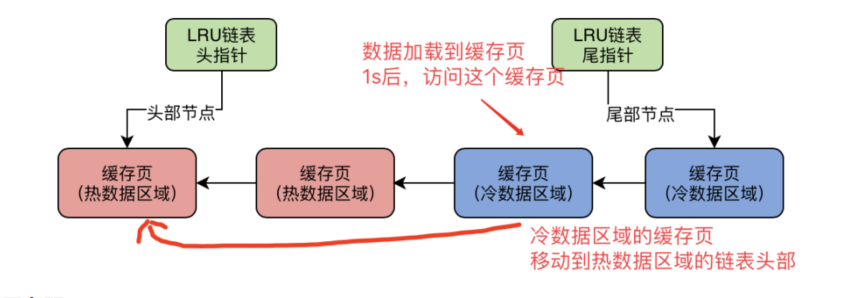
- 热数据区(young 区):63%,存放经常访问的数据
- 冷数据区(old 区):37%,存放新加载的数据
比例通过 innodb_old_blocks_pct 控制,默认 37%。
规则:
- 新加载的页放在冷数据区头部
- 冷数据区的页被访问后,如果超过 1 秒(
innodb_old_blocks_time默认 1000ms)还有再次访问,才移到热数据区头部 - 淘汰时从冷数据区尾部踢
这样预读和全表扫描进来的大批量数据,如果没有后续访问,就会待在冷数据区,被淘汰时也不会影响热数据。
热数据区的优化:前 1/4 的缓存页被访问时不移动到头部,后 3/4 才移动,减少频繁移动带来的性能开销。
这套冷热分离的设计思路挺值得借鉴的,Redis内存淘汰策略清单 里的 LRU 也是类似的思想。
4.1 举个例子:user 表 id=1 的旅程
假设 Buffer Pool 只有 10 个缓存页,冷数据区占 4 个(37% 取整),热数据区占 6 个。
第①步:第一次查询 SELECT * FROM user WHERE id = 1
user 表 id=1 的数据页不在 Buffer Pool,从磁盘加载,放到冷数据区头部,同时冷数据区尾部的 J 被淘汰:
加载前: 加载后:
热区:[A][B][C][D][E][F] 热区:[A][B][C][D][E][F] (不变)
冷区:[G][H][I][J]←淘汰点 冷区:[user][G][H][I]←淘汰点
↑ 新页放这里
第②步:Buffer Pool 继续被使用
又有新数据要加载,冷数据区尾部的 I 被淘汰,user 被挤到中间:
热区:[A][B][C][D][E][F]
冷区:[新数据][user][G][H]←淘汰点
第③步:1 秒内再次查询 user id=1
冷数据区的页被访问,但还没超过 1 秒,不会移到热数据区,只更新访问时间戳。这是为了防止全表扫描时,同一页在短时间被多次访问就误判为热点。
第④步:过了 1 秒后,再次查询 user id=1
超过 innodb_old_blocks_time(默认 1000ms)还有访问,提升到热数据区头部:
提升前: 提升后:
热区:[A][B][C][D][E][F] 热区:[user][A][B][C][D][E] ←user提升到这里
冷区:[新数据][user][G][H] 冷区:[新数据][G][H][F]←淘汰点
↑ 要提升的 ↑ F被挤到冷区
对比:如果是全表扫描会怎样?
全表扫描一次性加载大量数据页到冷数据区,但这些页只被访问一次,不会超过 1 秒再被访问,所以不会被提升到热数据区。等 Buffer Pool 需要空间时,这些冷数据从尾部依次被淘汰,热数据区的真正热点数据安然无恙。
热区:[A][B][C][D][E][F] ← 这些热点数据不受影响
冷区:[scan1][scan2][scan3][scan4]← 全表扫描数据,只访问一次,很快被淘汰
5. 脏页什么时候刷回磁盘?
有三种触发方式:
- 定时刷:后台线程定期把冷数据区尾部的一些缓存页刷回磁盘,释放回 free 链表
- flush 链表刷:后台线程定时把 flush 链表里的脏页刷盘,同时从 lru 链表移除,加入 free 链表
- 紧急刷:free 链表空了,没有空闲页了,从 lru 链表冷数据区尾部找一个缓存页强制刷盘,腾出位置
具体怎么配置多实例、chunk、生产环境参数,以及验证方法,见 [[Buffer Pool配置调优]]。