缓存一致性
1. 先说结论
只要用缓存,就一定会有短暂的数据不一致,但最终会一致。我们要做的就是尽量缩短不一致的时间。
两种方案:
- 追求性能:延迟双删(删缓存 → 更新 DB → 延迟再删缓存)
- 追求一致性:加分布式锁(加锁 → 删缓存 → 更新 DB → 更新缓存 → 解锁)
2. 为什么选延迟双删?
常见的缓存更新有两种方式:
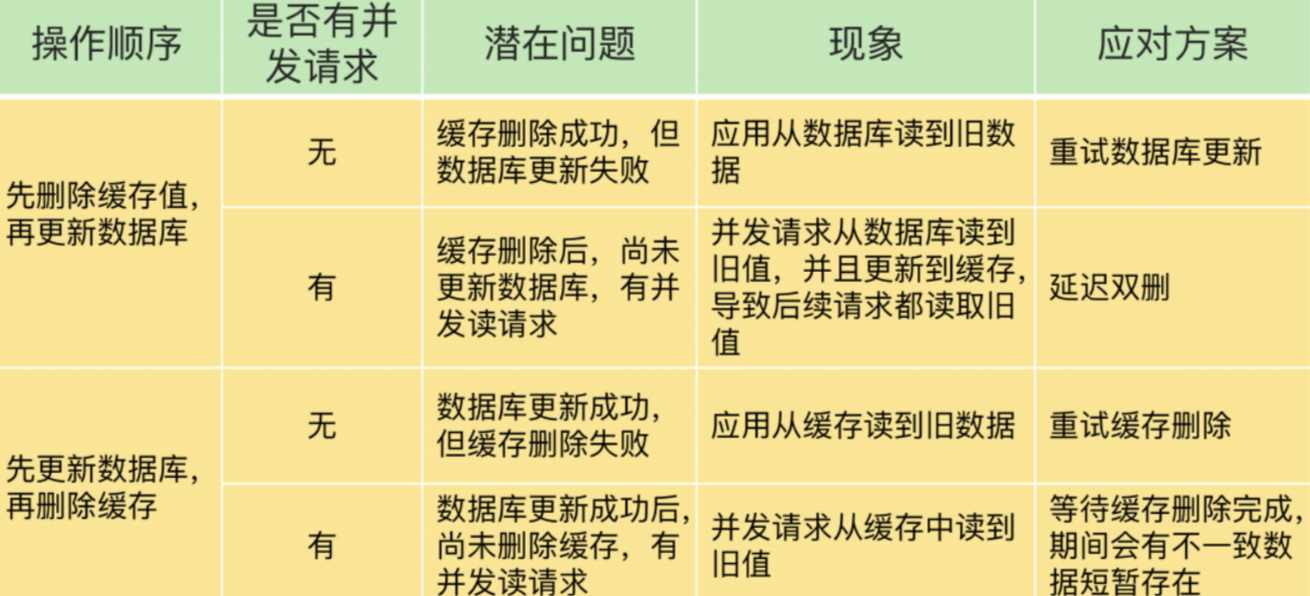
我们的系统基本都有并发请求,所以选择先删缓存,再更新数据库,同时做延迟双删。
2.1 延迟双删怎么做?
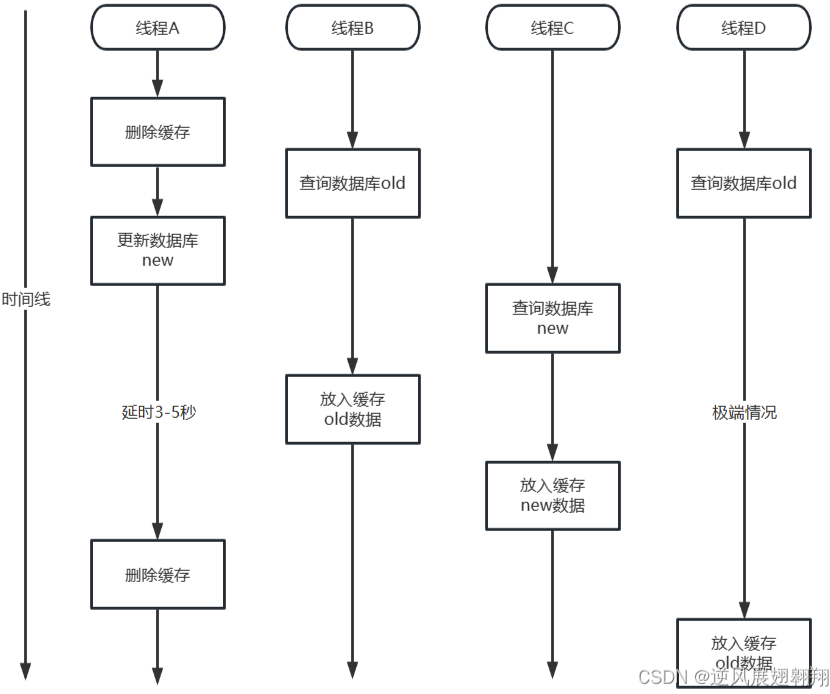
流程很简单:
- 删除缓存
- 更新数据库
- 等个几百毫秒(比如 500ms)
- 再删一次缓存
为什么要延迟再删一次?因为可能有并发的读请求刚好在更新数据库的时候查了旧数据,然后写回了缓存。延迟一下再删,就能把这个旧数据清掉。
2.2 还会有问题吗?
极端情况下还是可能不一致,但因为缓存操作很快,这种情况很难碰到。如果真的不能接受,那就用分布式锁。
3. 什么时候用分布式锁?
如果对数据一致性要求特别高(比如金融、库存),就得上分布式锁了。
3.1 场景 1:防止缓存击穿
缓存失效的时候,大量请求同时打到数据库,这就是缓存击穿。
解决办法:
发现缓存没数据 → 加锁 → 查数据库 → 写缓存 → 解锁
这样只有第一个请求去查数据库,其他请求等着,等缓存有数据了直接读缓存。
3.2 场景 2:保证更新时的一致性
更新数据的时候,用锁把整个流程保护起来:
加锁 → 删缓存 → 更新数据库 → 写新数据到缓存 → 解锁
这样就能保证缓存和数据库完全一致,但性能会下降。
3.3 用锁要注意什么?
- 锁一定要设置超时时间,不然服务挂了就死锁了
- 锁的粒度要细,针对具体的 Key 加锁,别搞全局锁
- 超时时间别设太短,建议 3-5 秒
4. 怎么选?
| 方案 | 一致性 | 性能 | 什么时候用 |
|---|---|---|---|
| 延迟双删 | 最终一致 | 快 | 大部分场景 |
| 分布式锁 | 强一致 | 慢一些 | 金融、库存等关键业务 |
简单记:
- 一般业务用延迟双删就够了
- 对数据要求特别严格的才用锁
- 用锁记得设超时